Service Design
SimpliRoute: rediseñar el servicio detrás del dashboard
Cómo apliqué service design para entender por qué los datos correctos no alcanzaban para tomar decisiones de entrega, y cómo rediseñamos la experiencia completa desde el dato hasta la acción.
Year :
2024
Industry :
Logística — SaaS
Client :
SimpleRoute
Rol :
Service Designer

Contexto
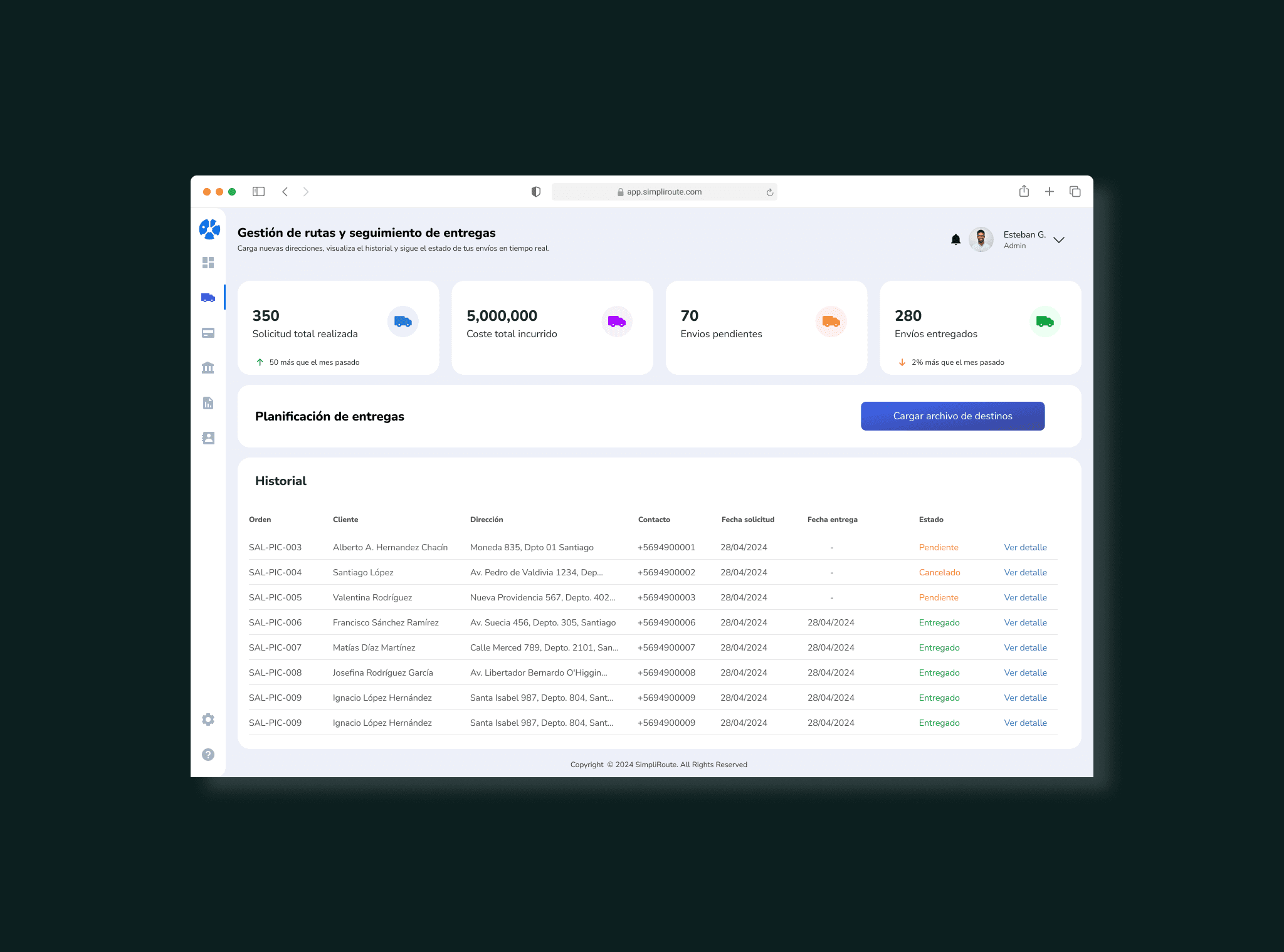
SimpliRoute es una plataforma SaaS de optimización logística. Su producto central es un dashboard donde los gestores de flota planifican rutas, monitorean entregas en tiempo real y toman decisiones operativas que afectan directamente los costos y la satisfacción del cliente final.
El dashboard tenía datos. Buenos datos. El problema era que los usuarios no podían convertir esos datos en decisiones rápidas. Cada vez que algo salía mal en una entrega, el gestor tenía que navegar entre múltiples vistas, contrastar información de distintas fuentes y tomar una decisión bajo presión de tiempo. El sistema informaba pero no facilitaba actuar.
El problema no era la falta de información. Era la distancia entre el dato y la acción. Eso es un problema de servicio, no solo de interfaz.
Los actores del servicio
Antes de tocar ningún wireframe, mapeamos todos los actores involucrados en el servicio de entrega. El dashboard no era usado por una sola persona: era el punto de intersección de múltiples roles con necesidades distintas y muchas veces en tensión.
Usuario principal 👨🏻💼 Gestor de flotaPlanifica rutas, monitorea el estado de entregas y resuelve incidencias en tiempo real. Alta presión operativa. | Usuario secundario 🚛 ConductorEjecuta la ruta asignada. Reporta problemas de dirección desde la app móvil. Sus datos alimentan el dashboard. | Cliente final 📦 DestinatarioRecibe la entrega. Su satisfacción depende de decisiones tomadas en el dashboard que nunca verá. |
|---|---|---|
Stakeholder interno 📊 Gerente de operacionesNecesita métricas de rendimiento. Consume los mismos datos que el gestor pero con una lógica completamente distinta. | Sistema externo 📍 Proveedores de mapasGoogle Maps, HERE y otros. La calidad de sus datos de dirección afecta directamente la tasa de entregas fallidas. | Soporte 📱 Equipo SimpliRouteRecibía tickets cuando los gestores no podían resolver incidencias desde el dashboard. Proxy de los pain points reales. |

El problema desde la perspectiva del servicio
El 40% de los problemas de entrega tenían su origen en direcciones incorrectas o incompletas. Pero el proceso para detectar, corregir y aplicar esas correcciones estaba fragmentado en múltiples pasos, herramientas y actores. El gestor era el eslabón que tenía que conectar todo eso manualmente.
Las direcciones incorrectas generaban el 50% de los retrasos en la planificación. El gestor las detectaba tarde, cuando el conductor ya estaba en ruta y había perdido tiempo. |
|---|
No había un flujo claro para corregir una dirección. El gestor tenía que salir del dashboard, buscar la dirección en herramientas externas, volver y actualizar manualmente. Cada corrección tomaba entre 3 y 7 minutos. |
Las correcciones no se aprendían. Si hoy se corregía una dirección, mañana volvía a aparecer incorrecta porque no había mecanismo para persistir ese conocimiento en el sistema. |
El dashboard mostraba el estado de las entregas pero no sugería acciones. El gestor veía que algo iba mal pero el sistema no le decía qué hacer ni en qué orden. |
Journey del gestor de flota
Mapeamos el journey completo del gestor durante una jornada de entregas con incidencias. Lo que encontramos fue que los momentos de mayor fricción no estaban en el dashboard en sí, sino en los puentes entre el dashboard y las acciones que el gestor tenía que tomar fuera de él.

Service Blueprint
El blueprint nos permitió ver el servicio completo en una sola vista: lo que el gestor experimenta en el frontend, lo que ocurre en el backstage del sistema, y los puntos de fallo entre ambas capas. Eso reveló que el problema de las direcciones incorrectas era un problema de sistema, no de UX de superficie.



Resultados
+35%Reducción en tiempo de resolución de incidencias | 98%Satisfacción en renovación de contrato |
|---|---|
+18%Mejora en tasa de entregas completadas | −12%Tickets de soporte por errores de dirección |
Mi proceso
Entrevistas con gestores y análisis de tickets
Empecé por entender el trabajo real del gestor de flota, no el trabajo ideal. Hice entrevistas contextuales mientras usaban el dashboard en vivo. Paralelamente, analicé los tickets de soporte de los últimos 3 meses para identificar los patrones de fallo más frecuentes. El 40% de los tickets tenían relación con direcciones incorrectas. Ese fue el punto de entrada.
Construcción del Service Blueprint
Mapeé el servicio completo en un blueprint: las acciones del gestor, lo que ve en el frontstage digital, lo que ocurre en el backstage del sistema y los procesos de soporte que sostenían los huecos del producto. Ese ejercicio reveló que el problema de las direcciones no era un bug de UI, era un problema de arquitectura de datos sin resolver en el backstage.
Definición de oportunidades de diseño
Del blueprint surgieron tres oportunidades concretas: mostrar un score de confianza por dirección antes de iniciar la ruta, integrar la corrección de direcciones dentro del dashboard sin salir a herramientas externas, y persistir las correcciones como aprendizaje del sistema. Cada oportunidad tenía un impacto distinto: la primera era de prevención, la segunda de eficiencia, la tercera de inteligencia acumulada.
Diseño de la solución en Figma
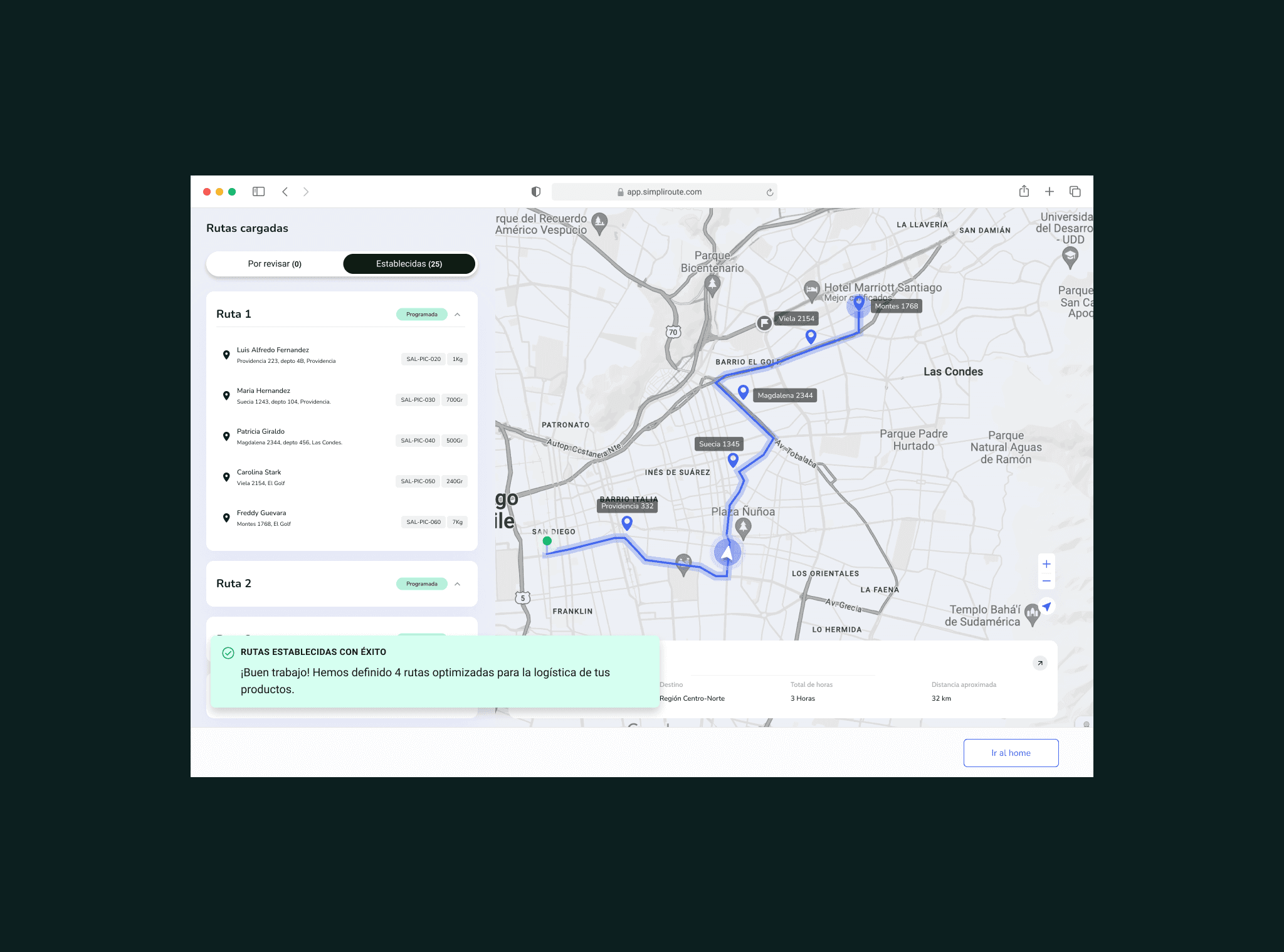
Diseñé tres features integradas: un indicador de riesgo por dirección en la vista de planificación, un flujo de corrección inline con validación automática vía API de mapas, y un panel de "direcciones frecuentes corregidas" que permitía al gestor gestionar el conocimiento acumulado del sistema. Cada feature se prototipó y validó con gestores reales antes de pasar a desarrollo.
Validación con usuarios y ajuste
Hicimos dos rondas de testing con gestores. La primera reveló que el score de riesgo necesitaba ser más explícito: los usuarios no entendían el número, necesitaban una categoría (bajo, medio, alto). La segunda confirmó que el flujo de corrección inline era viable pero necesitaba un paso de confirmación para evitar errores accidentales. Esos ajustes entraron antes del release.
Decisiones clave
La decisión más importante fue tratar el problema de direcciones como un problema de servicio y no como un problema de UI. Si solo hubiéramos mejorado cómo se mostraban los errores, el gestor habría seguido perdiendo tiempo corrigiéndolos manualmente. La solución tenía que atacar el ciclo completo: detectar, corregir y aprender.
La segunda decisión fue no diseñar para el caso ideal. En logística, siempre algo sale mal. El dashboard tenía que estar optimizado para el escenario de incidencias, no para el día perfecto en que todo llega a tiempo. Eso cambió completamente las prioridades de la interfaz: lo que necesitaba prominencia eran las alertas accionables, no las métricas de resumen.
El dashboard no fallaba en informar. Fallaba en facilitar actuar. Diseñar esa diferencia fue el trabajo real del proyecto.
Herramientas y métodos
Figma | Service Blueprint | Prototipado |
|---|---|---|
Journey Mapping | Entrevistas contextuales | Dashboard Design |
Análisis de tickets | Usability Testing | Data visualization |
Aprendizajes
El blueprint revela lo invisibleMapear el backstage del servicio fue lo que hizo visible el problema real. Sin ese ejercicio, habríamos rediseñado la interfaz sin resolver la causa raíz. | Diseña para el día maloEn operaciones, el caso de incidencia es el caso normal. Un dashboard logístico tiene que estar optimizado para cuando algo falla, no para cuando todo va bien. |
Los tickets son researchEl análisis de tickets de soporte fue más revelador que muchas entrevistas. Eran el registro honesto de dónde el servicio fallaba sin filtros ni sesgos de cortesía. | Informar no es suficienteUn buen dashboard no solo muestra lo que pasa. Sugiere qué hacer. La diferencia entre datos y decisiones es el diseño. |

Más proyectos






Service Design
SimpliRoute: rediseñar el servicio detrás del dashboard
Cómo apliqué service design para entender por qué los datos correctos no alcanzaban para tomar decisiones de entrega, y cómo rediseñamos la experiencia completa desde el dato hasta la acción.
Year :
2024
Industry :
Logística — SaaS
Client :
SimpleRoute
Rol :
Service Designer
Contexto
SimpliRoute es una plataforma SaaS de optimización logística. Su producto central es un dashboard donde los gestores de flota planifican rutas, monitorean entregas en tiempo real y toman decisiones operativas que afectan directamente los costos y la satisfacción del cliente final.
El dashboard tenía datos. Buenos datos. El problema era que los usuarios no podían convertir esos datos en decisiones rápidas. Cada vez que algo salía mal en una entrega, el gestor tenía que navegar entre múltiples vistas, contrastar información de distintas fuentes y tomar una decisión bajo presión de tiempo. El sistema informaba pero no facilitaba actuar.
El problema no era la falta de información. Era la distancia entre el dato y la acción. Eso es un problema de servicio, no solo de interfaz.
Los actores del servicio
Antes de tocar ningún wireframe, mapeamos todos los actores involucrados en el servicio de entrega. El dashboard no era usado por una sola persona: era el punto de intersección de múltiples roles con necesidades distintas y muchas veces en tensión.
Usuario principal 👨🏻💼 Gestor de flotaPlanifica rutas, monitorea el estado de entregas y resuelve incidencias en tiempo real. Alta presión operativa. | Usuario secundario 🚛 ConductorEjecuta la ruta asignada. Reporta problemas de dirección desde la app móvil. Sus datos alimentan el dashboard. | Cliente final 📦 DestinatarioRecibe la entrega. Su satisfacción depende de decisiones tomadas en el dashboard que nunca verá. |
|---|---|---|
Stakeholder interno 📊 Gerente de operacionesNecesita métricas de rendimiento. Consume los mismos datos que el gestor pero con una lógica completamente distinta. | Sistema externo 📍 Proveedores de mapasGoogle Maps, HERE y otros. La calidad de sus datos de dirección afecta directamente la tasa de entregas fallidas. | Soporte 📱 Equipo SimpliRouteRecibía tickets cuando los gestores no podían resolver incidencias desde el dashboard. Proxy de los pain points reales. |
El problema desde la perspectiva del servicio
El 40% de los problemas de entrega tenían su origen en direcciones incorrectas o incompletas. Pero el proceso para detectar, corregir y aplicar esas correcciones estaba fragmentado en múltiples pasos, herramientas y actores. El gestor era el eslabón que tenía que conectar todo eso manualmente.
Las direcciones incorrectas generaban el 50% de los retrasos en la planificación. El gestor las detectaba tarde, cuando el conductor ya estaba en ruta y había perdido tiempo. |
|---|
No había un flujo claro para corregir una dirección. El gestor tenía que salir del dashboard, buscar la dirección en herramientas externas, volver y actualizar manualmente. Cada corrección tomaba entre 3 y 7 minutos. |
Las correcciones no se aprendían. Si hoy se corregía una dirección, mañana volvía a aparecer incorrecta porque no había mecanismo para persistir ese conocimiento en el sistema. |
El dashboard mostraba el estado de las entregas pero no sugería acciones. El gestor veía que algo iba mal pero el sistema no le decía qué hacer ni en qué orden. |
Journey del gestor de flota
Mapeamos el journey completo del gestor durante una jornada de entregas con incidencias. Lo que encontramos fue que los momentos de mayor fricción no estaban en el dashboard en sí, sino en los puentes entre el dashboard y las acciones que el gestor tenía que tomar fuera de él.
Service Blueprint
El blueprint nos permitió ver el servicio completo en una sola vista: lo que el gestor experimenta en el frontend, lo que ocurre en el backstage del sistema, y los puntos de fallo entre ambas capas. Eso reveló que el problema de las direcciones incorrectas era un problema de sistema, no de UX de superficie.
Resultados
+35%Reducción en tiempo de resolución de incidencias | 98%Satisfacción en renovación de contrato |
|---|---|
+18%Mejora en tasa de entregas completadas | −12%Tickets de soporte por errores de dirección |
Mi proceso
Entrevistas con gestores y análisis de tickets
Empecé por entender el trabajo real del gestor de flota, no el trabajo ideal. Hice entrevistas contextuales mientras usaban el dashboard en vivo. Paralelamente, analicé los tickets de soporte de los últimos 3 meses para identificar los patrones de fallo más frecuentes. El 40% de los tickets tenían relación con direcciones incorrectas. Ese fue el punto de entrada.
Construcción del Service Blueprint
Mapeé el servicio completo en un blueprint: las acciones del gestor, lo que ve en el frontstage digital, lo que ocurre en el backstage del sistema y los procesos de soporte que sostenían los huecos del producto. Ese ejercicio reveló que el problema de las direcciones no era un bug de UI, era un problema de arquitectura de datos sin resolver en el backstage.
Definición de oportunidades de diseño
Del blueprint surgieron tres oportunidades concretas: mostrar un score de confianza por dirección antes de iniciar la ruta, integrar la corrección de direcciones dentro del dashboard sin salir a herramientas externas, y persistir las correcciones como aprendizaje del sistema. Cada oportunidad tenía un impacto distinto: la primera era de prevención, la segunda de eficiencia, la tercera de inteligencia acumulada.
Diseño de la solución en Figma
Diseñé tres features integradas: un indicador de riesgo por dirección en la vista de planificación, un flujo de corrección inline con validación automática vía API de mapas, y un panel de "direcciones frecuentes corregidas" que permitía al gestor gestionar el conocimiento acumulado del sistema. Cada feature se prototipó y validó con gestores reales antes de pasar a desarrollo.
Validación con usuarios y ajuste
Hicimos dos rondas de testing con gestores. La primera reveló que el score de riesgo necesitaba ser más explícito: los usuarios no entendían el número, necesitaban una categoría (bajo, medio, alto). La segunda confirmó que el flujo de corrección inline era viable pero necesitaba un paso de confirmación para evitar errores accidentales. Esos ajustes entraron antes del release.
Decisiones clave
La decisión más importante fue tratar el problema de direcciones como un problema de servicio y no como un problema de UI. Si solo hubiéramos mejorado cómo se mostraban los errores, el gestor habría seguido perdiendo tiempo corrigiéndolos manualmente. La solución tenía que atacar el ciclo completo: detectar, corregir y aprender.
La segunda decisión fue no diseñar para el caso ideal. En logística, siempre algo sale mal. El dashboard tenía que estar optimizado para el escenario de incidencias, no para el día perfecto en que todo llega a tiempo. Eso cambió completamente las prioridades de la interfaz: lo que necesitaba prominencia eran las alertas accionables, no las métricas de resumen.
El dashboard no fallaba en informar. Fallaba en facilitar actuar. Diseñar esa diferencia fue el trabajo real del proyecto.
Herramientas y métodos
Figma | Service Blueprint | Prototipado |
|---|---|---|
Journey Mapping | Entrevistas contextuales | Dashboard Design |
Análisis de tickets | Usability Testing | Data visualization |
Aprendizajes
El blueprint revela lo invisibleMapear el backstage del servicio fue lo que hizo visible el problema real. Sin ese ejercicio, habríamos rediseñado la interfaz sin resolver la causa raíz. | Diseña para el día maloEn operaciones, el caso de incidencia es el caso normal. Un dashboard logístico tiene que estar optimizado para cuando algo falla, no para cuando todo va bien. |
Los tickets son researchEl análisis de tickets de soporte fue más revelador que muchas entrevistas. Eran el registro honesto de dónde el servicio fallaba sin filtros ni sesgos de cortesía. | Informar no es suficienteUn buen dashboard no solo muestra lo que pasa. Sugiere qué hacer. La diferencia entre datos y decisiones es el diseño. |
Más proyectos
Service Design
SimpliRoute: rediseñar el servicio detrás del dashboard
Cómo apliqué service design para entender por qué los datos correctos no alcanzaban para tomar decisiones de entrega, y cómo rediseñamos la experiencia completa desde el dato hasta la acción.
Year :
2024
Industry :
Logística — SaaS
Client :
SimpleRoute
Rol :
Service Designer
Contexto
SimpliRoute es una plataforma SaaS de optimización logística. Su producto central es un dashboard donde los gestores de flota planifican rutas, monitorean entregas en tiempo real y toman decisiones operativas que afectan directamente los costos y la satisfacción del cliente final.
El dashboard tenía datos. Buenos datos. El problema era que los usuarios no podían convertir esos datos en decisiones rápidas. Cada vez que algo salía mal en una entrega, el gestor tenía que navegar entre múltiples vistas, contrastar información de distintas fuentes y tomar una decisión bajo presión de tiempo. El sistema informaba pero no facilitaba actuar.
El problema no era la falta de información. Era la distancia entre el dato y la acción. Eso es un problema de servicio, no solo de interfaz.
Los actores del servicio
Antes de tocar ningún wireframe, mapeamos todos los actores involucrados en el servicio de entrega. El dashboard no era usado por una sola persona: era el punto de intersección de múltiples roles con necesidades distintas y muchas veces en tensión.
Usuario principal 👨🏻💼 Gestor de flotaPlanifica rutas, monitorea el estado de entregas y resuelve incidencias en tiempo real. Alta presión operativa. | Usuario secundario 🚛 ConductorEjecuta la ruta asignada. Reporta problemas de dirección desde la app móvil. Sus datos alimentan el dashboard. | Cliente final 📦 DestinatarioRecibe la entrega. Su satisfacción depende de decisiones tomadas en el dashboard que nunca verá. |
|---|---|---|
Stakeholder interno 📊 Gerente de operacionesNecesita métricas de rendimiento. Consume los mismos datos que el gestor pero con una lógica completamente distinta. | Sistema externo 📍 Proveedores de mapasGoogle Maps, HERE y otros. La calidad de sus datos de dirección afecta directamente la tasa de entregas fallidas. | Soporte 📱 Equipo SimpliRouteRecibía tickets cuando los gestores no podían resolver incidencias desde el dashboard. Proxy de los pain points reales. |
El problema desde la perspectiva del servicio
El 40% de los problemas de entrega tenían su origen en direcciones incorrectas o incompletas. Pero el proceso para detectar, corregir y aplicar esas correcciones estaba fragmentado en múltiples pasos, herramientas y actores. El gestor era el eslabón que tenía que conectar todo eso manualmente.
Las direcciones incorrectas generaban el 50% de los retrasos en la planificación. El gestor las detectaba tarde, cuando el conductor ya estaba en ruta y había perdido tiempo. |
|---|
No había un flujo claro para corregir una dirección. El gestor tenía que salir del dashboard, buscar la dirección en herramientas externas, volver y actualizar manualmente. Cada corrección tomaba entre 3 y 7 minutos. |
Las correcciones no se aprendían. Si hoy se corregía una dirección, mañana volvía a aparecer incorrecta porque no había mecanismo para persistir ese conocimiento en el sistema. |
El dashboard mostraba el estado de las entregas pero no sugería acciones. El gestor veía que algo iba mal pero el sistema no le decía qué hacer ni en qué orden. |
Journey del gestor de flota
Mapeamos el journey completo del gestor durante una jornada de entregas con incidencias. Lo que encontramos fue que los momentos de mayor fricción no estaban en el dashboard en sí, sino en los puentes entre el dashboard y las acciones que el gestor tenía que tomar fuera de él.
Service Blueprint
El blueprint nos permitió ver el servicio completo en una sola vista: lo que el gestor experimenta en el frontend, lo que ocurre en el backstage del sistema, y los puntos de fallo entre ambas capas. Eso reveló que el problema de las direcciones incorrectas era un problema de sistema, no de UX de superficie.
Resultados
+35%Reducción en tiempo de resolución de incidencias | 98%Satisfacción en renovación de contrato |
|---|---|
+18%Mejora en tasa de entregas completadas | −12%Tickets de soporte por errores de dirección |
Mi proceso
Entrevistas con gestores y análisis de tickets
Empecé por entender el trabajo real del gestor de flota, no el trabajo ideal. Hice entrevistas contextuales mientras usaban el dashboard en vivo. Paralelamente, analicé los tickets de soporte de los últimos 3 meses para identificar los patrones de fallo más frecuentes. El 40% de los tickets tenían relación con direcciones incorrectas. Ese fue el punto de entrada.
Construcción del Service Blueprint
Mapeé el servicio completo en un blueprint: las acciones del gestor, lo que ve en el frontstage digital, lo que ocurre en el backstage del sistema y los procesos de soporte que sostenían los huecos del producto. Ese ejercicio reveló que el problema de las direcciones no era un bug de UI, era un problema de arquitectura de datos sin resolver en el backstage.
Definición de oportunidades de diseño
Del blueprint surgieron tres oportunidades concretas: mostrar un score de confianza por dirección antes de iniciar la ruta, integrar la corrección de direcciones dentro del dashboard sin salir a herramientas externas, y persistir las correcciones como aprendizaje del sistema. Cada oportunidad tenía un impacto distinto: la primera era de prevención, la segunda de eficiencia, la tercera de inteligencia acumulada.
Diseño de la solución en Figma
Diseñé tres features integradas: un indicador de riesgo por dirección en la vista de planificación, un flujo de corrección inline con validación automática vía API de mapas, y un panel de "direcciones frecuentes corregidas" que permitía al gestor gestionar el conocimiento acumulado del sistema. Cada feature se prototipó y validó con gestores reales antes de pasar a desarrollo.
Validación con usuarios y ajuste
Hicimos dos rondas de testing con gestores. La primera reveló que el score de riesgo necesitaba ser más explícito: los usuarios no entendían el número, necesitaban una categoría (bajo, medio, alto). La segunda confirmó que el flujo de corrección inline era viable pero necesitaba un paso de confirmación para evitar errores accidentales. Esos ajustes entraron antes del release.
Decisiones clave
La decisión más importante fue tratar el problema de direcciones como un problema de servicio y no como un problema de UI. Si solo hubiéramos mejorado cómo se mostraban los errores, el gestor habría seguido perdiendo tiempo corrigiéndolos manualmente. La solución tenía que atacar el ciclo completo: detectar, corregir y aprender.
La segunda decisión fue no diseñar para el caso ideal. En logística, siempre algo sale mal. El dashboard tenía que estar optimizado para el escenario de incidencias, no para el día perfecto en que todo llega a tiempo. Eso cambió completamente las prioridades de la interfaz: lo que necesitaba prominencia eran las alertas accionables, no las métricas de resumen.
El dashboard no fallaba en informar. Fallaba en facilitar actuar. Diseñar esa diferencia fue el trabajo real del proyecto.
Herramientas y métodos
Figma | Service Blueprint | Prototipado |
|---|---|---|
Journey Mapping | Entrevistas contextuales | Dashboard Design |
Análisis de tickets | Usability Testing | Data visualization |
Aprendizajes
El blueprint revela lo invisibleMapear el backstage del servicio fue lo que hizo visible el problema real. Sin ese ejercicio, habríamos rediseñado la interfaz sin resolver la causa raíz. | Diseña para el día maloEn operaciones, el caso de incidencia es el caso normal. Un dashboard logístico tiene que estar optimizado para cuando algo falla, no para cuando todo va bien. |
Los tickets son researchEl análisis de tickets de soporte fue más revelador que muchas entrevistas. Eran el registro honesto de dónde el servicio fallaba sin filtros ni sesgos de cortesía. | Informar no es suficienteUn buen dashboard no solo muestra lo que pasa. Sugiere qué hacer. La diferencia entre datos y decisiones es el diseño. |